2021 was the second annual Data-Centric Architecture Forum. As a signatory of the Data Centric Manifesto, and the creator of a data platform, I was there to give a product spotlight, and was also looking forward to seeing the latest developments in data-centric thinking and technology.
 I wasn't disappointed, gaining insights into data fabrics and knowledge graphs, backed by customer case studies, and seeing the immense progress made by vendors of supporting products.
I wasn't disappointed, gaining insights into data fabrics and knowledge graphs, backed by customer case studies, and seeing the immense progress made by vendors of supporting products.
The event was held virtually, with a full three-day agenda. Produced by Semantic Arts, it featured the data-centric architectural approach described in. Semantic Arts president Dave McComb's book The Data Centric Revolution.
The content that was presented and discussed included:
- What data-centric architecture is
- How to overcome barriers to adoption of data-centric architecture
- Customer case studies of data-centric architecture deployment
- Vendor presentation of products that could be data-centric architecture components.
Highlights
My highlghts from the event included:
Dave McComb's "top and tail" presentations on what data-centric architecture is and how to adopt it by overcoming application-centric inertia.
- The presentation by Ben Gardner and Tom Plasterer of AstraZeneca describing a real-life application of data-centric principles and use of semantic technology, knowledge graph, and data mesh. They aim to serve "data citizen, rather than data scientist."
- Mike Pool of Morgan Stanley's vision of a semantic consortium - a group of organisations, each with its own domain ontology, managing inter-relationdships and overlaps between their ontologies using a common core ontology.
- The very clear explanation by Michael Gruninger of the University of Toronto in his presentation on Ontologies in the Enterprise of the fundamental semantic problems that arise in data integration. (Is your "customer" the same as my "customer" . . . ?) He proposed to overcome the problems by gradual evolution of the differing ontologies to resolve conflicts.
- Dan Gschwend's presentation of Amgen's data fabric with three layers - data generation, consolidation, and semantic. The semantic layer is organized as a map of data domains, each with a conceptual information model and an ontology. The domain ontologies "snap together" to provide a combined overall understanding of the data.
- The presentation by Max Leonard and Hannes Ricklefs, explaining how the BBC uses linked data and knowledge graphs to help journalists build interesting web pages. They also had some interesting thoughts on handling personal data, and the use of the Solid architecture proposed by Tim Berners-Lee.
- The discussions of data marketplaces and decentralized identity in the final session on "The Future of Data-Centric", moderated by independent consultant Alan Morrison.
Technical Takeaways
Key technical concepts included data-centric, semantics, data fabrics, data meshes, and knowledge graphs.
Data-Centric
A data-centric architecture is one where data is the primary and permanent asset, and applications come and go. In a data centric architecture, the data model precedes the implementation of any given application and will be around and valid long after it is gone.
While making data the primary asset does not necessarily imply a single central data model, this is a core principle for enterprise adoption of data-centric architecture. In his book The Data-Centric Revolution, Dave McComb writes, "A data-centric enterprise is one where all application functionality is based on a single, simple, extensible data model." Drawing on his extensive experience, he argues that most enterprises have data models that are excessively complex, and that they need just a few hundred core concepts, with relatively modest specialist extensions.
Semantics
"The Web was designed as an information space, with the goal that it should be useful not only for human-human communication, but also that machines would be able to participate and help. One of the major obstacles to this has been the fact that most information on the Web is designed for human consumption, and even if it was derived from a database with well defined meanings (in at least some terms) for its columns, that the structure of the data is not evident to a robot browsing the web. Leaving aside the artificial intelligence problem of training machines to behave like people, the Semantic Web approach instead develops languages for expressing information in a machine processable form." (Tim Berners-Lee).
The semantic web standards were developed by the World Wide Web Consortium to enable machines to participate in the Web by interpreting and processing its information. They include the Resource Description Framework (RDF), the query language SPARQL, and the Web Ontology Language (OWL). RDF says how to identify and describe things and the relationships between them. It does this using subject-verb-object triples; repositories of RDF descriptions are triple stores. SPARQL says how to obtain specific information by querying a store of RDF descriptions. OWL says how to describe relationships between classes of objects and their properties.
The semantic web standards are crucial to the architecture described in the Data Centric Revolution. Within an enterprise, a core ontology is the basis of the central data model by which collections of disparate data can be viewed as a central whole. Semantic Arts provides such an ontology - gist - for use, with minor extensions, in any enterprise.
Data Fabrics
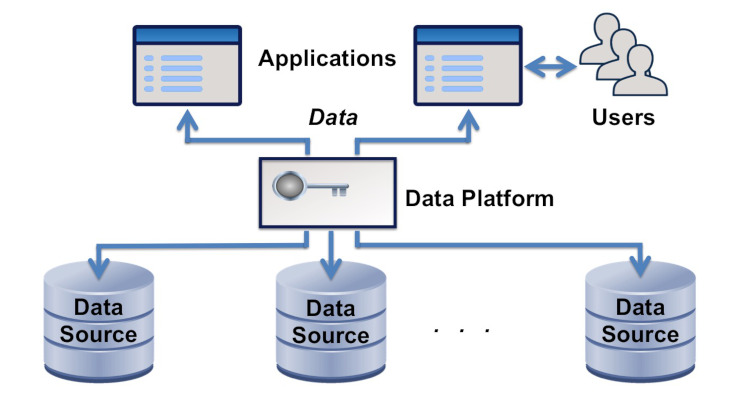
A data fabric is an architected system that provides uniform access to data held in multiple, disparate sources. It has an application interface, and often also a user interface. It gives the ability to write data, as well as to read it. The sources may be on-premise or in the cloud. Relatively few enterprises have data fabrics today, but their use is growing.
Data platforms are products that connect to multiple sources and provide access to their data. They are key components of data fabrics. They may import data from the sources but more usually, and more effectively, they use data virtualization. In either case, they transform the source data to fit a target schema, or expose the source schema to applications.
In a data-centric architecture with a single central data model, the source data should ideally follow that model and not require transformation.
Transformation of data from different sources to fit a common schema or model is achieved by schema mapping that uses metadata to describe the common model and schema, and to relate it to the source schema. The Semantic Web RDF and OWL standards are the most powerful metadata standards today, and arguably the only sensible choice. Data platforms in semantic data fabrics follow these standards, and are based on triple stores. The metadata of a semantic data fabric includes OWL ontologies. It may also include knowledge graphs.
Data Meshes
The concept of data mesh is slightly different to that of data fabric. A data mesh consists of data products, each of which meets a set of user needs and has assured levels of quality and security. It has domain-oriented de-centralized data ownership and management.
Within an enterprise, the data products could be incorporated into a data-centric architecture with a common model in the same way as sources in a data fabric.
Knowledge Graphs
The first knowledge graph was used by Google to make web searches more intelligent and to augment the results with information relevant to the query. They are used in other applications that interpret natural language, such as devices that respond to voice commands. Increasingly they are also used in enterprise data fabrics for data discovery and schema mapping.
A knowledge graph is a graph in the sense of a set of nodes connected by edges, not in the sense of a plotted relation such as hospital admissions over time. The nodes are objects. They can include object classes, connected to member objects by "is a" or "has type" edges, e.g. "John is a person". In some knowledge graphs, the edges have attributes, such as "probability" or "intensity" (e.g. "John likes [with intensity 80%] cats").
What is the difference between a knowledge graph and an ontology? An ontology specifies relationships between object classes, relationships between properties, and relationships between object classes and properties. It is thus a kind of knowledge graph, whose nodes are object classes amd properties. The term knowledge graph is however generally used when most of its nodes are ordinary objects, particularly words and phrases, not object classes or properties. A knowledge graph can usually be represented using RDF, and does not need the power of the ontology language OWL.
Knowledge graphs may be held in triple stores but, for performance reasons, graph databases are generally used.
Conclusions
An enterprise where all application functionality is based on a single, simple, extensible data model is the ideal for efficient data management and use, but most enterprises today are not like that. When an enterprise develops a new business area, its innovators introduce new concepts. These may not actually be new, or they may be closely related to existing concepts, but this is not discovered until later. Speed of deployment is more important than semantic consistency; serious problems will need to be addressed in the future, but having the business fail now by coming late to market is a bigger worry. A large enterprise usually has business areas that have developed independently, perhaps in other enterprises that it has acquired, each with applications and data based on concepts that appear different but actually are not. The problems of semantic consistency are real. They reduce the efficiency of the enterprise. They are a hidden tax on business profits.
The cost is no longer hidden when the enterprise wants to integrate data from different applications. Analytics and reporting is a common reason for this, and a whole range of data integration technologies have been developed to meet this need. Another common reason is the acquisition of a company in a similar business area, leading to a need to integrate its customer and other data into the data of the acquiring enterprise.
How can these costs be avoided or reduced? Adoption of a core data model and architectural refactoring to align other data models with it, using the kind of process described by Michael Gruninger, is one way. But evolution is slow, and refactoring the applications that use the data models is expensive. Adoption of a data fabric or data mesh, using data platforms to transform the data "on the fly", is a quicker option, leaving existing applications untouched. This solution follows the data-centric principle that data is the primary and permanent asset and applications come and go. It enables an enterprise to have a single, central data model, and also to use applications that do not follow that model.
The event had a strong showing of data platform products. They do not necessarily have all the required features yet, but there are enough of them, with enough capabilities, to demonstate that a data fabric or mesh is a viable strategy, and to show its benefits.
Knowledge graphs have value, regardless of whether your architecture is data-centric, particularly in relating what potential customers are talking about to what your enterprise does. In a data-centric architecture, they can also enable powerful metadata management, and contribute to schema translation. The reluctance of enterprises to spend money up-front on aligning their data with common models when the benefits will not be seen until later has always been a drag on the adoption of data integration technology. By automating the alignment process, and making it easier to use by data engineers who are not semantic specialists, data platforms with knowledge graphs can reduce this drag.
One test of a good event is how far it moves your understanding of its subject matter. If you are thinking the same way at the end of the event as you did at the beginning, what have you gained? DCAF 2021 certainly passed this test, developing my understanding of data-centric, semantics, data fabrics, data mesh, and knowledge graphs, and changing some of my views. I'm looking forward to next year's event.