Embeddings are vectors that represent words or sentences.
They typically have several hundred dimensions. (768 is common). In programming terms, an embedding is represented as a list of (e.g.) 768 floating-point numbers.
So a word that might have an ASCII representation of 5 bytes is given an embedding representation of 5K bytes. What's the point?
Words with similar embeddings have similar meanings. Similarity of two embeddings can be calculated by a mathematical operation. This enables applications such as semantic search and clustering.
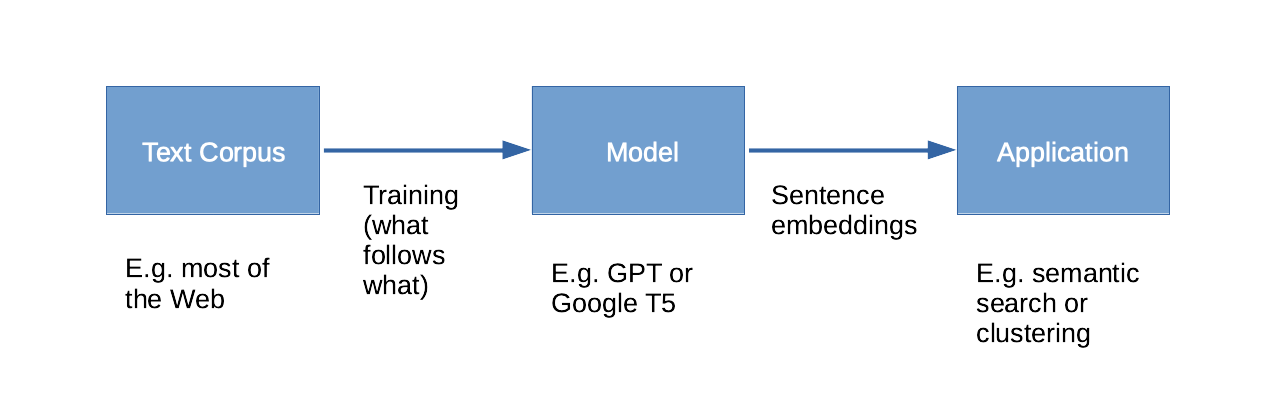 The figure shows how sentence embeddings are produced. Word embeddings are produced in a similar way.
The figure shows how sentence embeddings are produced. Word embeddings are produced in a similar way.
Knowledge graph embeddings are produced by training a model using a knowledge graph.
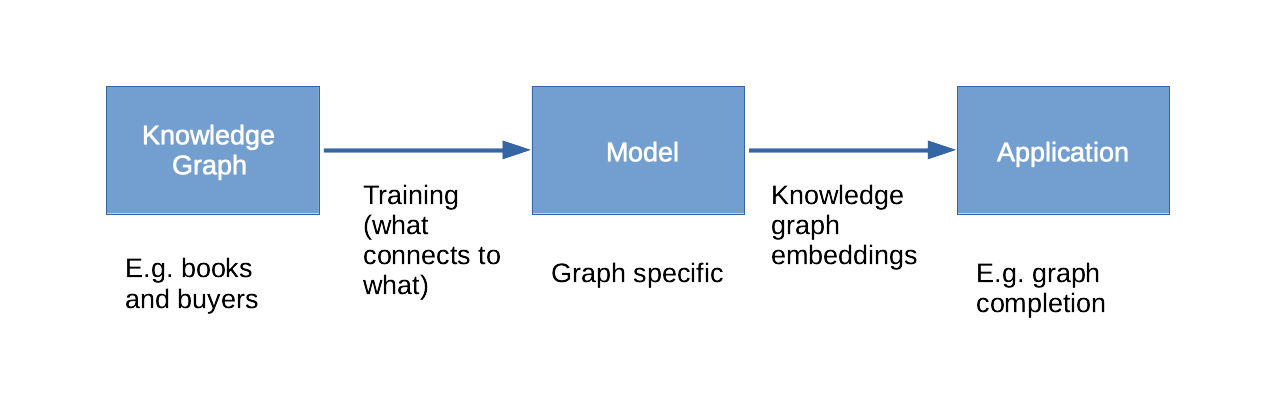
The knowledge graph embeddings include vectors that represent the nodes and the edges of the graph. A mathematical operation on a node-edge-node triple of representations gives the closeness of fit of that triple with the pattern defined by the other triples of the graph. This can be used, for example, to estimate the probability that two nodes should be joined by an edge, even if the edge isn't actually in the graph.